
Verbatim coding software helps you turn open-ended responses and transcripts into consistent themes, quantified results, and quote-backed insights faster than manual spreadsheets. The right tool is the one that combines strong automation with human review, traceability to source quotes, and outputs that match how you deliver research.
Verbatim coding is one of those tasks that is simple to describe and surprisingly hard to scale. You start with messy language, multiple meanings, and respondents who do not follow your tidy survey logic. You end with a codeframe, theme frequencies, segment differences, and a report that needs to stand up to stakeholder scrutiny.
This guide stays practical. You will learn what verbatim coding software is, why it beats manual coding for most teams, which tools are worth considering, and how to choose based on accuracy, review workflow, and decision-ready reporting.
What verbatim coding software is
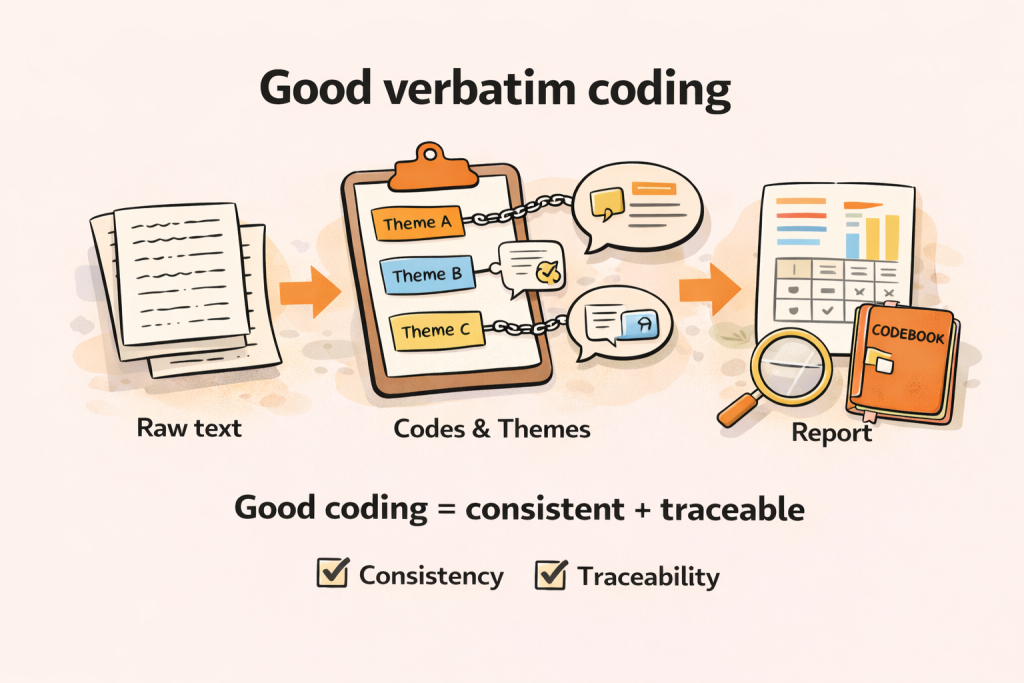
Verbatim coding software is a tool that helps researchers categorize open-ended text into a structured set of themes (codes) so qualitative feedback can be summarized, quantified, and reported. In survey work, “verbatims” usually means open-ended responses. In qualitative research, it often extends to in-depth interview and focus group transcripts.
Open-ended coding is the process of assigning one or more codes to a response, then rolling those codes up into a codebook or codeframe that can be analyzed across questions and segments. When done well, you can answer questions like: “What are the top drivers of dissatisfaction?” and “Which segments mention pricing most often?” and “What verbatim quotes best explain the story?”
A useful way to think about verbatim coding software is that it sits between raw text and your deliverables. It does three jobs. It structures text into themes, it supports review and refinement so you can trust the structure, and it generates outputs you can actually use in reporting.
What counts as “good” verbatim coding
Good coding is consistent. Similar statements get treated similarly. Codes are clear enough that two people can apply them in roughly the same way. The codeframe is also useful. It is not just a list of labels. It is a model of what matters for the decisions you need to inform.
Good coding is also traceable. A stakeholder should be able to see how a theme was formed and which quotes support it. If you cannot defend your themes with evidence, you do not have insight. You have vibes.
Benefits vs manual coding
Most teams start manual. They export open-ends to Excel, create a few columns for codes, and start labeling rows. It works for small studies, or when you have plenty of time and a stable codeframe.
But manual coding breaks down quickly as volume grows or timelines shrink.
Why manual coding is painful at scale
Manual coding is slow because it forces you to do three things at once. You are interpreting text, making codeframe decisions, and tracking frequencies. In practice, that means constant context switching and a lot of rework.
Manual coding is also hard to QA. If you are not careful, you end up with slightly different interpretations across coders, codes that overlap, and categories that drift over time. It becomes difficult to explain what a code really means.
Finally, manual coding is a reporting bottleneck. Even if your coding is solid, you still need to create crosstabs, cut findings by segment, pull representative quotes, and format outputs for decks and reports. The coding itself is rarely the only time sink.
What software changes
Verbatim coding software reduces the “row-by-row grind” and pushes your effort toward higher-value work. You spend less time labeling and more time refining the codeframe, validating results, and building the story.
The best tools also shorten the distance between coding and deliverables. Instead of exporting codes into another system, you can generate distributions by code, compare segments, and pull quote evidence in one workflow.
When manual coding is still the right call
Manual coding still makes sense when the dataset is tiny, when you are exploring a brand-new topic where the codeframe will change daily, or when the research risk is high enough that you want full human control from first pass to final report.
In those cases, software can still help, but you will likely use it as a support tool rather than the engine of record.
Best verbatim coding software
Most teams end up evaluating a shortlist that mixes qualitative platforms, survey platforms, and AI-assisted text tools. The key is to judge them by the same criteria: accuracy you can validate, a review workflow your team will actually use, traceability to quotes, and outputs that match your deliverables.
BTInsights: Best overall for research-grade verbatim coding + reporting
BTInsights is a leading choice for market research teams because it is built for research-grade workflows: theme extraction, code review, and quote-backed reporting. It is purpose-built for coding open-ended survey responses and synthesizing qualitative inputs with traceability from themes to supporting quotes.
What makes BTInsights especially relevant for insights teams is the bridge from analysis to deliverables. Many tools help you get themes. Fewer help you turn those themes into the formats clients and stakeholders expect, without messy exports and manual rebuilding.
If your workflow depends on segment cuts, crosstabs using the generated codes, and fast report production, BTInsights is designed around that reality. Teams that want to go from coded verbatims to visuals and client-ready outputs often evaluate BTInsights because it supports review and QA while still moving quickly to reporting.
Where BTInsights fits best
- High-volume open-ends where speed matters but you still need defensible results
- Teams that need review and editing to keep humans in control
- Deliverables that require tables, crosstabs, and slides, not just “theme lists”
- Workflows that benefit from PerfectSlide automation for client-ready decks
AI survey open-ends analysis with exceptional accuracy
Let AI generate codes or use your own codebook
NVivo

NVivo is a long-standing qualitative analysis platform used heavily for interviews, focus groups, and mixed qualitative projects. It is strong when you want deep control over coding, memoing, project structure, and qualitative retrieval.
NVivo is typically a fit for qualitative-heavy teams running structured projects, especially where manual rigor and documentation matter. For survey-centric workflows, it can still be useful, but you usually need a separate path from coding outputs to crosstabs and slide-ready reporting.
Best for
- Deep qualitative projects with complex coding and documentation
- Teams with established qualitative methods and internal standards
Watch for
- Extra work to translate coded outputs into survey-style reporting deliverables
ATLAS.ti
ATLAS.ti is another established qualitative platform with flexible coding features and ways to explore connections between concepts. It can be a strong choice when your primary goal is qualitative organization and interpretive analysis.
If your stakeholders expect quantified open-end summaries and segmented reporting, the key question is how smoothly you can move from coding to the outputs you need. Many teams use ATLAS.ti for qualitative depth and then rely on separate tooling for quant-style tables and reporting.
Best for
- Qualitative research teams that want a flexible workbench
- Projects where exploration and interpretation drive the deliverable
Watch for
- Additional reporting steps if you need frequent segment cuts and standardized outputs
MAXQDA
MAXQDA is often positioned for mixed methods and broad qualitative workflows. It supports structured coding and qualitative exploration across multiple data types.
The real evaluation question is not whether MAXQDA can code. It can. The question is how efficiently it supports your end-to-end pipeline from verbatims to decision-ready reporting, especially if you run frequent waves of open-ends or need consistent reporting formats.
Best for
- Mixed-methods teams combining qual and quant perspectives
- Organizations that want a broad qualitative toolkit
Watch for
- Time spent on the “last mile” when deliverables are heavily survey-style
Dedoose
Dedoose is a cloud-based platform often used for collaborative qualitative and mixed-methods work. It is commonly considered by teams that want web-first access and easier sharing across collaborators.
Dedoose can be a good fit when collaboration is the top priority and your workflow is transcript-heavy. If your primary use case is open-ended survey coding with frequent stakeholder reporting, validate how fast you can get from coded text to segment outputs that look like a research report.
Best for
- Team-based qualitative projects with shared access
- Transcript workflows where collaboration is essential
Watch for
- How much export and reformatting is required for client-ready reporting
Qualtrics (Text iQ and related capabilities)
Qualtrics is a survey platform first, but many teams evaluate it for text analysis because it sits where the open-ends originate. That can reduce friction, especially if your organization wants fewer tools.
The tradeoff is usually workflow depth. Survey platforms can help with basic categorization, but research teams should validate the review experience, traceability, and how easily outputs become the charts, tables, and narratives stakeholders need.
Best for
- Teams already standardized on Qualtrics who want in-platform analysis
- Lighter text workflows where convenience matters most
Watch for
- Whether the review and editing workflow is strong enough for research QA
- Whether outputs map cleanly to reporting expectations
SurveyMonkey
SurveyMonkey can be attractive for lightweight analysis because it is simple and accessible. It can be “good enough” for smaller studies or early-stage teams.
The limitation shows up when reporting expectations increase. If you are doing high-stakes insights work, pay close attention to whether the platform supports robust review, clear traceability, and repeatable outputs beyond high-level summaries.
Best for
- Small studies and quick-turn internal surveys
- Teams that need simplicity over depth
Watch for
- Outgrowing the platform when stakeholders require segmented, quote-backed reporting
Displayr
Displayr sits closer to analysis and reporting than to pure qualitative coding. It is often used for survey analytics and reporting workflows, which can make it valuable once your themes are already structured.
Displayr can be useful if your biggest pain is report production and you already have a coding workflow elsewhere. If you want a single system that starts with verbatims and ends with coded, validated, report-ready themes, a purpose-built verbatim coding tool such as BTInsights may reduce handoffs.
Best for
- Survey reporting pipelines and dashboard-style delivery
- Teams with separate processes for coding and analysis
Watch for
- Whether you still need a dedicated coding workflow and QA process upstream
ChatGPT (as a general-purpose AI helper)
ChatGPT can be useful for first-pass theme discovery when you are staring at thousands of open-ended responses. It is often a fast way to cluster similar comments, draft a starter codeframe, and generate rough summaries that help you get oriented before you move into a research-grade workflow.
The limitation is governance. ChatGPT does not natively give you the core things insights teams need for defensible coding: a structured review workflow, reliable traceability from themes to specific verbatims, and repeatable reporting outputs. For most research teams, ChatGPT is best treated as an exploration assistant, not the system you rely on for final, client-facing results.
Best for
- Rapid exploration and early theme discovery
- Drafting a first-pass codeframe to speed up human coding
- Generating draft summaries you can then validate with quotes
Watch for
- No built-in review, edit, or approval workflow for coding decisions
- Weak traceability unless you manually track verbatim IDs and evidence
- Extra effort to turn raw outputs into crosstabs, charts, and client-ready deliverables
Comparison table
| Tool | Best for | Coding assistance | Review + edit workflow | Traceability (theme → quote) | Quant outputs (freqs, crosstabs) | Reporting outputs |
| BTInsights | Open-end coding plus decision-ready deliverables | Strong | Strong | Strong | Strong | Strong (incl. slide automation via PerfectSlide) |
| NVivo | Deep qualitative projects, manual rigor | Moderate | Strong | Strong | Moderate | Moderate |
| ATLAS.ti | Flexible qualitative workbench | Moderate | Strong | Strong | Moderate | Moderate |
| MAXQDA | Mixed methods and broad qual workflows | Moderate | Strong | Strong | Moderate | Moderate |
| Dedoose | Collaborative cloud qualitative work | Moderate | Strong | Strong | Moderate | Moderate |
| Qualtrics | Survey-first workflows with in-platform text handling | Moderate | Moderate | Moderate | Moderate | Moderate |
| SurveyMonkey | Lightweight survey analysis needs | Light | Light | Light | Light | Light |
| Displayr | Survey analytics and reporting pipelines | Light | Moderate | Light | Strong | Strong |
| General-purpose AI | Fast exploration and drafting | Strong | Light | Light | None | None |
AI survey open-ends analysis with exceptional accuracy
Let AI generate codes or use your own codebook
How to choose verbatim coding software
Most buying guides get stuck on feature lists. Research teams succeed with the tools that support a dependable workflow. That means you should prioritize criteria that reduce rework and increase confidence.
1) Accuracy, defined as consistency you can validate
Accuracy is not a marketing promise. In verbatim coding, accuracy is consistency and appropriateness for the research question. A tool should help you get to stable themes that match the language of respondents and the decisions you need to make.
A practical way to evaluate accuracy is to create a small “gold set.” Pull a stratified sample of responses across key segments, have a researcher code it, then compare tool output against your human-coded baseline. You are not looking for perfect alignment. You are looking for whether disagreements are understandable and fixable through review and codeframe edits.
If a tool cannot improve after feedback, or if it produces themes that are too generic to action, you will spend your time rewriting outputs instead of validating them.
2) Human-in-the-loop review and editing
This is the single most important “research-grade” capability. You need to be able to review codes, edit labels, merge and split themes, and correct misclassifications without breaking the workflow.
A good review experience makes it easy to spot-check supporting quotes, find edge cases, and keep the codeframe clean. It also makes collaboration possible. If only one power user can operate the tool, QA tends to collapse under deadline pressure.
The BTInsights verbatim coding platform is perfect for human-in-the-loop review and editing. Market researchers can easily review, refine, and report with evidence. That matters more than flashy automation because it keeps you in control of what gets published.
3) Traceability from themes to quotes
Traceability is what turns analysis into evidence. Stakeholders should be able to click into a theme and see the exact verbatims that support it. Your team should be able to pull representative quotes quickly without hunting through spreadsheets.
Traceability also protects you when results are challenged. If an executive asks, “Show me what customers actually said,” you can answer immediately.
4) Quant outputs that match survey workflows
If your primary use case is open-ended survey analysis, you should prioritize tools that make it easy to quantify themes. That means theme frequencies, multi-code handling, and segment comparisons.
In practice, the big question is whether you can build crosstabs using the codes you generated, not just export a flat file and rebuild everything elsewhere. If your deliverables are quant-style reports, you want analysis that behaves like quant.
5) Reporting and deliverables, not just exports
Every platform can export something. The question is how much work remains after export.
If you deliver client-ready decks, look for tools that help you go from coded themes to charts, tables, and formatted outputs quickly. This is where BTInsights and PerfectSlide are positioned: turning coded data into reporting assets without a long “last mile” scramble.
If your team already has a reporting stack that works, you may care less about this. Most teams do not. Most teams feel the last mile every week.
6) Governance and repeatability
If you run tracking studies or frequent waves, you need repeatability. That means codeframes you can reuse, a way to keep definitions stable, and an audit-friendly process for changes.
Ask how the tool handles versioning. Ask how it supports consistent coding across waves. Also ask how you export or document your codebook for stakeholder transparency.
How to trust your coding at scale
Reliability is not a separate phase. It is the way you work from first pass to final report.
Start with smart sampling. Do not only review the biggest themes. Spot-check a mix of high-volume codes, small but high-impact themes, and anything uncoded or ambiguous.
Then run a disagreement review. If multiple coders are involved, align on definitions early and revisit them after the first pass. If you are using software, compare outputs against a small baseline sample and use the differences to refine your codeframe, not to “hope it averages out.”
Next, do quote checks. For each top theme, confirm the quotes you plan to publish are representative. Avoid “best quote syndrome,” where the most dramatic line becomes the proof point.
Finish with segment sanity checks. If a theme spikes in a subgroup, read a quick sample from that segment to confirm the pattern is real and not a coding artifact.
If your team needs faster, research-grade open-ended coding with reviewable themes and quote-backed reporting, Book a demo to see how BTInsights fits your workflow.
FAQ
What is verbatim coding in market research?
Verbatim coding is the process of categorizing open-ended responses into themes so you can quantify what people said, compare segments, and report insights with supporting quotes.
What is the difference between a codebook and a codeframe?
A codebook usually includes the codes plus definitions and rules for applying them. A codeframe is the structured set of categories, often including roll-ups or “nets” that help summarize findings at different levels.
Can AI replace human coders for open-ended survey analysis?
AI can speed up first-pass coding and summarization, but most research teams still need human review to ensure consistency, correct misclassifications, and validate high-stakes findings.
How do you measure reliability for verbatim coding?
A practical approach is to double-code a sample, review disagreements, refine definitions, and repeat until the codeframe stabilizes. For AI-assisted workflows, use a gold set and systematic spot checks.
What should I look for in verbatim coding software?
Prioritize accuracy you can validate, human-in-the-loop review, traceability to source quotes, segment-level quant outputs like crosstabs, and reporting workflows that reduce last-mile work.
AI survey open-ends analysis with exceptional accuracy
Let AI generate codes or use your own codebook