
Open-ended survey responses are where the “why” lives. They also tend to be the messiest part of analysis: thousands of verbatims, mixed topics, multiple languages, and stakeholders who want segment cuts and a deck by Friday.
Survey text analysis software exists to solve that, but the category is crowded and the labels are confusing. Some tools are built for market research coding workflows, some are survey platforms with add-on text analytics, and some are general NLP products that require heavy setup before they produce research-ready outputs.
This guide helps you choose the right option for market research teams in 2026. You’ll get a practical evaluation rubric, a workflow you can use to test any platform, and a curated list of tool types (with examples) so you can match software to how your team actually works.
What “survey text analysis” means in market research
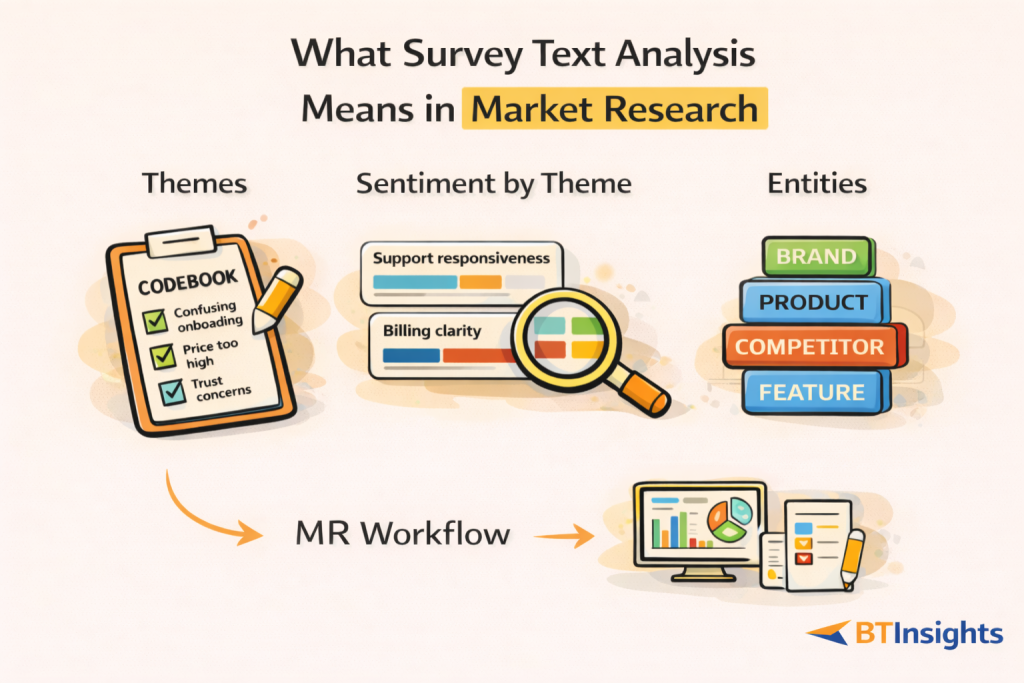
In market research, survey text analysis is not “run sentiment and call it done.” It is the structured process of turning raw verbatims into outputs that can be quantified, validated, and reported with confidence.
The three outputs teams actually need
Most MR teams end up needing three kinds of outputs from open-ended responses:
Themes (coding into a codeframe).
Responses are tagged with one or more codes that represent a topic or reason, such as “price too high,” “confusing onboarding,” or “trust concerns.”
Sentiment distribution by theme.
Sentiment alone is rarely useful but sentiment attached to a theme is. That is how you learn that “support responsiveness” is mostly positive while “billing clarity” is mostly negative.
Entities (brand, product, competitor, feature names).
Some questions are not about themes. They are about lists: “Which brands do you consider?” “What tools do you use?” “Which competitors did you evaluate?” Entity extraction needs different handling than thematic coding.
Where it fits in a modern MR workflow
Survey text analysis typically sits between fieldwork and reporting, but it touches more steps than most teams expect:
You collect verbatims, clean them, align them to metadata (segment, market, wave), code them into themes, quantify those themes across key cuts, then produce deliverables: charts, tables, and evidence-backed insight summaries with quotes.
When software is doing its job, it reduces time spent on manual tagging, makes coding consistent across waves and analysts, and speeds up reporting without cutting corners on validation.
When survey text analysis breaks down
Even strong tools need guardrails. Common failure modes include:
Short, low-context answers (“fine,” “ok”), multi-topic responses that should be multi-coded, sarcasm and negation (“great, another app update”), and small segment base sizes that make patterns look bigger than they are.
A good platform does not eliminate these issues. It makes them visible and reviewable.
Common use cases market research teams run in 2026

Market research teams tend to reuse a handful of open-end patterns. Knowing your primary use case helps you choose the right tooling.
NPS and CSAT verbatims
This is the classic “why did you score us this way?” workflow. You need fast coding, consistent codeframes over time, and trend reporting.
The most useful output is usually: top drivers of detractors, what is changing wave over wave, and which themes differ by plan type, region, or customer tenure.
Concept and ad testing
These studies often include recall, comprehension, and “what would you change?” questions. The responses can be nuanced and multi-part.
You want software that supports multi-label coding, quick sub-coding for specific creative elements, and easy quote extraction for creative teams.
Brand tracking and U&A studies
Tracking requires governance. If your codeframe drifts each wave, the trend becomes meaningless.
Here, the tool choice is less about flashy AI features and more about versioning, reviewer workflows, and repeatability.
Product feedback and post-launch surveys
These often mix structured questions with open-ends about friction points. The value comes from connecting text to quant cuts: “Which issues drive low satisfaction among new users?” and “Which features are mentioned most by enterprise accounts?”
The best tools make it easy to go from a theme to the supporting verbatims, then to a segment cut that proves the theme is not anecdotal.
The tools, grouped by “best for”
One reason these “top tools” articles feel unhelpful is that they mix categories. A survey platform with basic text analytics is not competing for the same job as a research-focused coding tool.
Here is a cleaner map.
Research-focused survey text analysis platforms
Best for teams that need: codeframes, multilingual coding, human review, quant cuts, quote extraction, and reporting outputs in one place.
Survey platforms with built-in text analytics
Best when you want everything inside the survey platform and your needs are lighter: quick theme summaries, basic sentiment, and simple exports.
Enterprise VoC and experience platforms
Best for organizations that unify survey, feedback, and operational data. Strong on dashboards and operations, but sometimes less flexible for research-style codebook governance.
Qualitative analysis tools that can support surveys
Best when your team combines interviews, focus groups, and survey verbatims, and you want a single qualitative repository. Watch for limited quant crosstabs.
General NLP platforms and APIs
Best for teams with data science resources who want full control. Powerful, but you are responsible for building review workflows and market research reporting layers.
AI survey open-ends analysis with exceptional accuracy
Let AI generate codes or use your own codebook
Top survey text analysis software for market research in 2026
To keep comparisons fair, each tool below includes: best for, what it does well, and what to watch out for. The goal is to help market research teams choose software that supports real workflows: coding open-ends, validating outputs, connecting text to quant cuts, and producing decision-ready deliverables.
BTInsights: Best overall for market research workflows
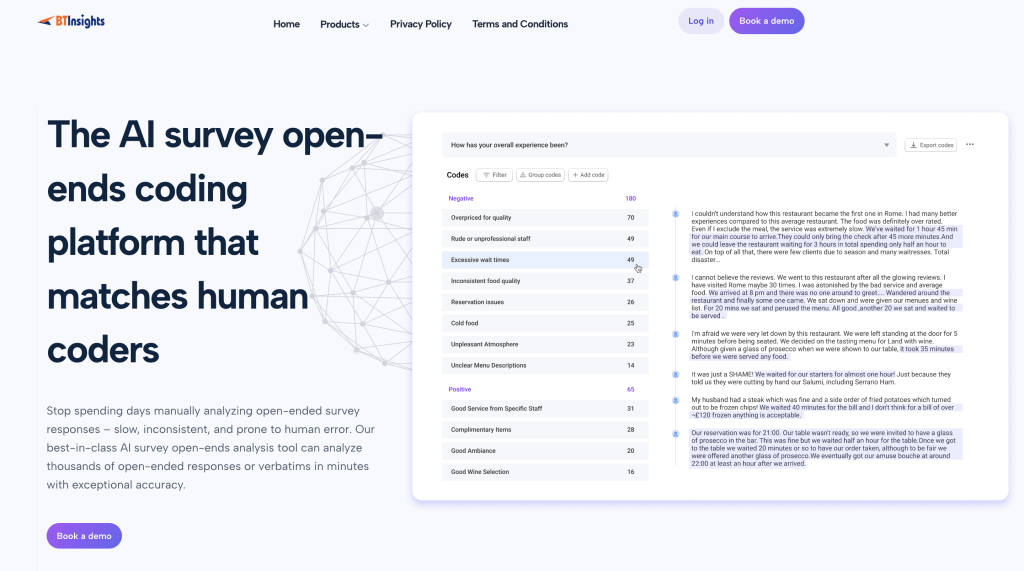
Best for: Market research teams analyzing open-ended responses at scale who need the strongest end-to-end workflow: coding, review, crosstabs, and slide-ready outputs.
BTInsights is the most complete option for MR teams because it is built around how research actually gets delivered. It helps you turn verbatims into a usable codeframe, quantify themes across key segments, and produce reporting that stays tied to evidence (quotes and bases). It is a top choice when you need both speed and governance, especially across large datasets, multiple questions, and multi-market studies where consistency matters.
Highlights
- Flexible coding: Start with an AI-suggested codebook or apply your own existing codeframe for trackers and brand programs
- Entity coding: Handles “Which brands do you consider?” by extracting a comprehensive set of named entities (not just themes)
- Multilingual analysis (50+ languages): Supports global studies where comparability across markets matters
- Human-in-the-loop review: Robust workflows to review, edit, and refine codes so outputs are defensible and usable in deliverables
- Reporting and visualization: Generate charts, build crosstabs using codes, and export visuals into PowerPoint formats aligned to MR reporting
What to watch out for: No tool is perfect on every dataset. What matters is consistency plus review controls, so nuanced meaning can be validated and documented without slowing the team down.
Ascribe
Best for: Teams that want an established name in qualitative and text analysis workflows, especially when blending qualitative research processes with structured outputs.
Ascribe is often considered by research teams that care about organizing text data in a structured way. For survey text analysis, the key is whether it supports market-research-grade workflows end to end: codebook management, multi-label coding, and then smooth translation of codes into quant outputs and reporting.
Highlights
- Qual-friendly structure: strong orientation toward organizing and interpreting text
- Codebook discipline: useful if your team runs consistent coding practices across studies
- Good candidate for mixed-method work: when survey verbatims sit alongside other qualitative inputs
What to watch out for
- Validate how efficiently it supports segment cuts (crosstabs) and reporting exports, especially if your deliverables are deck-heavy
- Test multi-label coding on messy verbatims (multi-topic responses, hedging, mixed sentiment)
Qualtrics (Text iQ)
Best for: Organizations already using Qualtrics that want text analytics inside their existing survey ecosystem.
Text iQ is usually chosen for convenience and governance: fewer handoffs, simpler access controls, and the ability to keep collection and analysis in one environment. That can be a strong advantage for enterprise teams that prioritize centralization.
Highlights
- Ecosystem fit: integrates naturally if survey ops and dashboards already live in Qualtrics
- Governance-friendly: easier stakeholder access and fewer tools to manage
- Fast for directional reads: useful when your goal is quick insight inside the same platform
What to watch out for
- If you need nuanced codeframes, custom taxonomy rules, or heavier review workflows, validate flexibility
- Confirm whether traceability is strong enough for MR deliverables (base sizes, quote linkage, code governance)
SurveyMonkey (text analysis capabilities)
Best for: Smaller teams that want basic open-end summarization inside a widely used survey tool.
SurveyMonkey’s built-in capabilities can work well for lightweight use cases where you need a fast sense of what people are saying, without a deep coding program. Many teams start here, then outgrow it when reporting demands increase.
Highlights
- Low friction: easy to stay in one tool for fieldwork and basic analysis
- Quick theming: good for rapid, directional summaries
- Accessible for non-technical teams: minimal setup
What to watch out for
- Tracker-grade needs (stable codeframes, governance) can push you into exports and manual work
- Deep segment comparisons and slide-ready reporting may require additional tooling
Alchemer (survey workflow plus analysis add-ons)

Best for: Teams that prioritize flexible survey workflows and want a path to text analysis without adopting a specialist platform immediately.
Alchemer can be a good choice when your primary focus is survey execution flexibility, and text analysis is a secondary need. It can also suit teams that want to evolve into deeper analysis later.
Highlights
- Survey workflow flexibility: strong when your team needs customized logic and workflows
- Pragmatic stepping stone: start with lighter analysis, then expand as needs mature
- Good for operational teams that also do MR: when survey ops and research overlap
What to watch out for
- Validate whether analysis outputs meet MR standards: codebook control, multi-label coding, and defensible reporting artifacts
- Confirm what’s possible around segment cuts and exports before committing
Medallia
Best for: Enterprises running ongoing experience programs where survey feedback is one signal among many.
Medallia’s strength is operationalization: governance, dashboards, and routing workflows at enterprise scale. For MR teams, the decision is whether your needs are closer to continuous CX monitoring or research-style analysis with codeframes and deliverables.
Highlights
- Enterprise operational strength: governance, workflows, and stakeholder visibility
- Good for ongoing programs: where feedback is continuous and multi-channel
- Scales across orgs: helpful when many teams need access to the same signals
What to watch out for
- MR teams should validate whether the text layer supports research-style coding (codebooks, review/adjudication)
- If your primary output is a research deck, confirm the path from analysis to slide-ready deliverables is efficient
InMoment
Best for: Organizations combining feedback sources with experience management dashboards.
InMoment can be attractive for centralizing experience signals and making them visible across the organization. For MR-style work, the key question is whether it supports the rigor and flexibility needed for research coding and reporting.
Highlights
- Centralized experience view: useful for continuous programs
- Dashboard-first orientation: good for ongoing visibility and stakeholder access
- Operational alignment: helpful when insights need to drive workflow changes
What to watch out for
- Test codeframe governance and review workflows if you run trackers or formal MR studies
- Validate reporting exports and “evidence traceability” for research deliverables
NVivo

Best for: Researchers who want deep qualitative coding control and are comfortable with more manual setup.
NVivo is widely used for qualitative research. It can support survey text datasets, especially when you want strong manual coding control, memos, and a classic qual workflow. The tradeoff tends to be speed and the tightness of the quant connection.
Highlights
- Strong qualitative coding controls: detailed tagging and structured qualitative workflows
- Good for researcher-driven analysis: when method rigor and annotation matter
- Useful for deep dives: smaller datasets or studies where interpretation is central
What to watch out for
- If you need fast segment cuts and reporting automation, validate how much work it takes to get there
- Ensure your team has time and process maturity for consistent coding at scale
MAXQDA
Best for: Teams that want strong qualitative workflows and need to incorporate survey text into broader qualitative analysis.
MAXQDA supports robust qualitative coding and can handle survey text datasets well, particularly when survey verbatims are part of a broader qual program (interviews, diaries, communities). As with other qual-first tools, MR teams should confirm the quant reporting layer.
Highlights
- Robust qual workflow: strong coding and organization features
- Works well in mixed-method contexts: when survey text sits alongside other qual data
- Good for method-driven teams: when structure and documentation matter
What to watch out for
- Validate quantified summaries and segment cuts, not just coding
- Confirm reporting outputs match how your team presents results (charts, tables, deck flow)
Amazon Comprehend (or similar NLP APIs)
Best for: Data science-led teams that want customizable pipelines and are willing to build the MR workflow layer.
General NLP APIs can handle building blocks like language detection, entity extraction, and classification. What they typically do not provide is the full market research workflow: codeframe governance, human review UI, traceability from chart to quote, and deck-ready reporting.
Highlights
- Highly customizable: you control taxonomy, pipelines, and integration
- Good for engineering-heavy orgs: if you already build internal analytics tools
- Strong for components: language detection and entities can be useful primitives
What to watch out for
- You will likely need to build (or stitch together) the review workflow and reporting layers
- Time-to-value can be slower than MR-native platforms unless you have dedicated resources
RapidMiner (or similar analytics platforms)

Best for: Teams with analytics capabilities that want to combine text, structured data, and modeling in one environment.
Analytics platforms can be powerful when your organization treats survey text as one input into broader modeling and decisioning. The key for MR is whether the platform supports the practical needs of codeframes, review, and reporting without heavy custom work.
Highlights
- Powerful for advanced analysis: integrates text with broader analytics
- Flexible pipelines: strong when you have analysts building repeatable workflows
- Good for hybrid needs: text plus modeling or other data sources
What to watch out for
- MR workflows often require additional layers (review UI, codebook governance, evidence traceability)
- Pilot with a realistic dataset to see whether setup effort matches the value
A practical “how to run it” workflow to test any tool
This workflow is your differentiator. It also makes your tool evaluation more reliable, because you are testing the full path from data to deliverable.
Step 1: Clean and structure open-ends
Start with a CSV that includes verbatims plus the metadata you actually report on: market, segment, product line, wave, NPS group, and any key demographics.
Remove duplicates and obvious junk responses. Keep a separate “excluded” flag rather than deleting rows, so bases remain auditable.
If the study is multilingual, ensure each response has a language field, even if it is inferred.
Step 2: Build a starter codeframe that matches the decision
A useful codeframe is not “everything people said.” It is the set of themes that answer the business question.
Combine deductive and inductive inputs:
Deductive: themes you already expect (pricing, usability, support).
Inductive: new themes that emerge (a new competitor, an unexpected friction point).
If this is a tracker, define what must remain stable across waves and what can evolve.
Step 3: Code with review rules, not vibes
Define how multi-topic responses should be handled. In most MR contexts, multi-label coding is essential. A single response can mention onboarding friction and pricing, and both should be captured.
Set explicit rules for edge cases:
Sarcasm, negation, mixed sentiment, and “it depends” statements.
This is where human-in-the-loop matters. You want the tool to accelerate coding, then make it easy to review and correct the tricky items.
Step 4: Quantify and cut by segment
Once coding is done, connect it to quant analysis:
Theme incidence overall and by key segments.
Sentiment distribution by theme.
Entities by frequency, then entities by segment.
A practical pattern for MR deliverables is:
Trend → Driver → Action
Trend: “Satisfaction dropped in Segment B.”
Driver: “Mentions of ‘billing clarity’ doubled among detractors.”
Action: “Fix invoice labeling and clarify renewal terms in onboarding emails.”
If a platform cannot support this chain, it is not a great fit for market research reporting, even if it can “summarize text.”
Step 5: Turn outputs into a deck with evidence
Your stakeholders usually need three things:
A clear takeaway statement.
A quantified chart or table.
A small set of supporting quotes that represent the pattern.
Look for platforms that keep this traceability intact: click from chart to verbatims, and export charts in the format your team uses.
Pitfalls to avoid when choosing a tool
Many teams buy the wrong tool because the demo looks good and the workflow reality is hidden.
One pitfall is choosing generic NLP and discovering you still need to build review processes, codebook governance, and reporting outputs from scratch.
Another pitfall is over-weighting “sentiment” and under-weighting codeframes. Sentiment without themes is rarely decision-ready.
Multilingual studies introduce their own risks. Do not assume translation makes themes comparable. Validate comparability across markets.
Finally, watch for tools that produce insights you cannot export cleanly. If your team lives in PowerPoint, the export workflow matters as much as the model.
FAQ
What is survey text analysis in market research?
It is the process of turning open-ended survey responses into structured outputs, typically themes, sentiment by theme, and entities, so they can be quantified and reported with traceable evidence.
What’s the difference between text analytics and thematic coding?
Text analytics is a broad term that can include sentiment and keyword extraction. Thematic coding focuses on mapping responses to a codeframe so you can quantify drivers and compare across segments and waves.
How do you validate AI coding for open-ended responses?
Use a spot-check protocol across key segments, review edge cases (sarcasm, negation, multi-topic answers), and document codeframe rules. Human review workflows make this efficient.
Can survey text analysis handle multilingual responses?
Yes, many tools support multilingual analysis, but you should validate comparability across markets. A practical test is to run the same question across languages and review theme alignment.
How do you connect open-ended themes to crosstabs?
Codes become variables, just like multiple-choice answers. You can then build distributions and crosstabs of codes by segment, wave, or any metadata field.
AI survey open-ends analysis with exceptional accuracy
Let AI generate codes or use your own codebook