
Open-ended survey responses are where the “why” lives, but they are also where project timelines quietly die. A few thousand verbatims turns into days of manual coding, supervisor checks, codeframe debates, and last-minute charting that never quite matches the story you want to tell.
If you use Ascribe (or you are evaluating it) and you are considering switching, the key question is not “which tool has AI.” In 2026, almost everyone says they have AI. The real question is: which platform helps you produce coding that stands up to scrutiny, connects cleanly to quant, and ships into a deck without weeks of cleanup.
This guide walks through five strong Ascribe alternatives for coding open-ended survey responses, with a practical decision rubric, a side-by-side comparison, and a pilot plan you can reuse.
What Ascribe is (and what it does well)
Ascribe (by Voxco) positions itself as a text analytics and verbatim coding management solution for open-end analysis, built for coding large volumes of open-ended responses and managing coding workflows.
If your team runs high-volume trackers, ad tests, or brand health studies with heavy open-ends, tools like Ascribe exist for a reason: they are designed around codeframes, coder assignments, supervisor review, and producing structured outputs for downstream analysis.
Ascribe has also been in the market a long time, which matters for some buyers who value established processes and familiarity.
So why switch?
Why teams look for Ascribe alternatives

Review sites are not perfect for niche market research tools, but they do reveal repeatable “paper cut” problems that add real cost when you are coding at scale.
UI and navigation overhead
Some users describe the interface as dated and harder to work in day to day. A common frustration is needing too many steps to get from a code assignment back to the original verbatim, which slows down review and quality checks.
Codeframe management gets harder as it grows
Another thread of feedback is that codeframes can become harder to keep organized as they expand. When you have a large taxonomy, finding, maintaining, and consistently applying the right codes can start to feel cumbersome.
Faster iteration from raw text to report-ready outputs
More broadly, teams increasingly expect a tighter loop from raw open-ends to quantified findings by segment, then into visuals and reporting outputs. Complaints about extra clicks, codeframe complexity, and workflow friction tend to point to the same underlying gap: the process feels slower than the modern expectation for turning text into decision-ready deliverables.
None of this means Ascribe is “bad.” It means the bar has moved, and many teams now prioritize platforms that are simpler to operate, more AI-forward, and more tightly connected to reporting workflows.
What to look for in an Ascribe alternative in 2026

Before you compare tools, align on what “better” means for your workflow. Here is a rubric that works well for MR and insights teams.
1) Coding quality you can validate
The right question is not “does it auto-code,” it is:
Can you test it on your hardest verbatims (multi-topic responses, sarcasm, negation, brand mentions), and can your team review and correct outputs efficiently?
2) Codeframe control (without friction)
Look for:
How codebooks are created (deductive, inductive, hybrid), how easy it is to merge/split codes, manage hierarchies, and keep naming consistent across waves.
3) Human-in-the-loop review that is actually usable
You want:
Fast review of edge cases, the ability to override labels, and a clear audit trail from theme back to verbatim.
4) Quant-ready outputs (and segmentation)
Open-ends become valuable when you can answer:
Which themes over-index among detractors, switchers, new users, Region A, Segment B?
That means reliable exports and crosstab-friendly outputs, not just a word cloud.
5) Reporting and visualization
A modern workflow should help you generate:
Theme distribution charts, segment cuts, example verbatims, and “what to do next,” without exporting five files and stitching them manually.
6) Cost and procurement fit
A practical reality: many established MR tools use custom pricing, which can be fine, but newer platforms often compete on pricing transparency or lower total cost, depending on seats and volume. Ascribe Coder is commonly described as custom-priced.
Quick comparison table
Use this as a starting point, then validate with a pilot (more on that later).
| Tool | Best for | Text coding approach | Review workflow | Reporting strength | Notes to verify |
| BTInsights | MR teams coding survey open-ends at scale | AI-assisted coding with editable outputs, codebook options | Strong focus on review/edit | Strong focus on quant outputs + reporting workflows | Validate on your hardest categories and required exports |
| Qualtrics Text iQ | Qualtrics-first orgs | Topics + sentiment + dashboards | Built into Qualtrics analysis flow | Strong in-platform widgets | Verify depth of codeframe control for MR-style codebooks |
| Caplena | Dedicated survey open-end coding programs | AI-assisted coding, interactive topic discovery | Designed for iterative refinement | Strong exploration, filtering, and quantifying | Validate complex nuance handling and governance needs |
| Thematic | Feedback analytics teams (VoC style) | Themes + sentiment with editing | Theme editor, drill-down to raw feedback | Strong dashboards and slicing | Check fit for strict MR coding specs and exports |
| Forsta (Genius Text Analytics) | Enterprise VoC, research programs in Forsta ecosystem | Categorization + sentiment add-on | Model setup + categorization workflow | Strong program reporting | Verify setup effort for models and how it handles survey coding needs |
The 5 best Ascribe alternatives for coding open-ended survey responses
A quick note on tone: “best” depends on your constraints. The right choice is the one that fits your workflow, governance needs, and reporting expectations. Each option below includes a best-fit scenario, where it tends to win, and what to test so you are not surprised after procurement.
1) BTInsights: Best overall Ascribe alternative for research-grade coding plus reporting
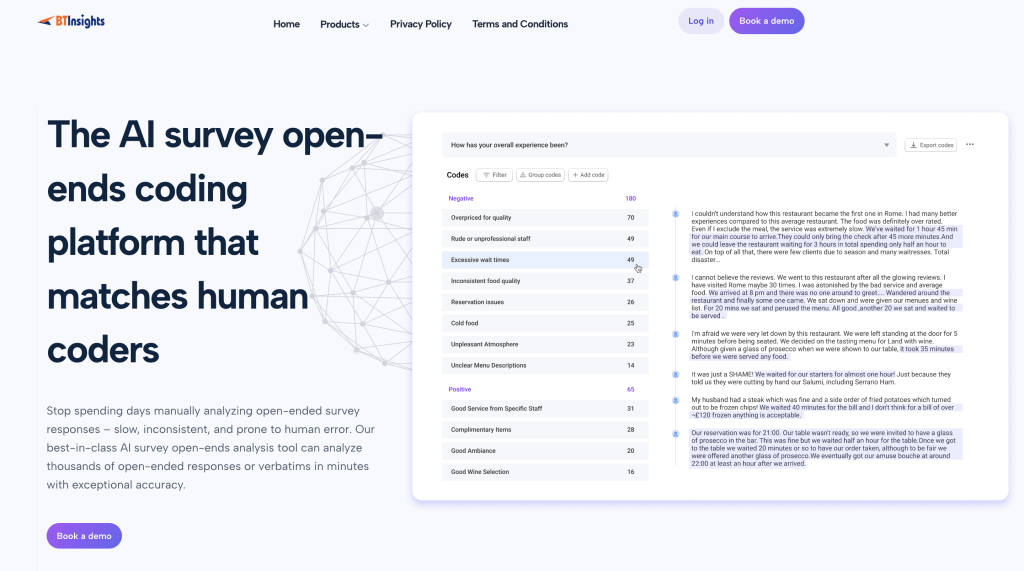
Best for: Market research and insights teams that need to code open-ended survey responses quickly, then turn them into quantified findings and reporting outputs with a reviewable workflow.
Why teams pick it instead of Ascribe:
BTInsights is often the top pick for research teams that need more than “tagging text.” It is built around an AI-assisted survey open-ends workflow, with analyst control through review and editing. In practice, it tends to fit teams who care about three outcomes:
First, getting from raw verbatims to a usable codeframe faster, especially with thousands of responses, multiple questions, or multiple languages. Multilingual handling plus review and edit steps are part of the core workflow, so teams can move quickly without sacrificing consistency.
Second, keeping outputs research-grade. That means you can trace themes back to supporting verbatims, pull quotes for reporting, and refine codes without turning the project into a rework spiral. This matters most when your codeframe evolves mid-project or across waves and you still need comparability you can defend.
Third, producing deliverables. For many teams, the real cost is not the first coding pass, it is everything that follows: quantifying themes, cutting them by segment, and translating the story into charts and slides stakeholders will actually use. BTInsights is designed for that end-to-end path, so you can go from themes to crosstab-ready outputs and report-friendly visuals in one workflow, not a patchwork of exports.
What to test in a pilot:
- Run a benchmark set of 300–500 verbatims that include your messiest data (multi-topic, sarcasm, negation).
- Measure how quickly analysts can correct outputs and converge on a stable codebook.
- Validate exports and crosstab readiness for your standard reporting workflow.
- Confirm multilingual handling if that matters to you.
AI survey open-ends analysis with exceptional accuracy
Let AI generate codes or use your own codebook
2) Qualtrics Text iQ
Best for: Teams already running surveys in Qualtrics who want integrated text analytics without adding a separate system.
What it is:
Text iQ is Qualtrics’ text analysis capability, typically used to apply topics and sentiment and surface results through reporting elements inside the Qualtrics environment.
Where it can beat Ascribe:
If your workflow already lives inside Qualtrics, Text iQ reduces tool switching. You can connect open-ended insights directly to your existing dashboards, segments, and reporting structures with less exporting and reformatting.
It can also make alignment easier internally: “analysis stays in our survey platform.”
Tradeoffs to watch:
The key question is rigor and governance. Many MR teams need deeper control than “topics” alone, especially for client deliverables, trackers, and codeframes that must remain consistent across waves. Verify that the structure and editing controls match your coding spec, not just a dashboarding use case.
What to test in a pilot:
- Recreate one of your standard open-end deliverables end-to-end inside Qualtrics.
- Validate how topics and sentiment translate into crosstabs and client-ready charts.
- Test what happens when you need to merge, split, or rename codes midstream.
3) Caplena
Best for: Teams that do a lot of survey open-end coding and want a dedicated, AI-assisted workflow for building and refining codeframes quickly.
What it is:
Caplena is positioned around automating survey coding and speeding codebook creation, with an interactive refinement loop that helps analysts adjust categories over time. It’s often evaluated by teams that want modern UX and faster iteration on a codeframe.
Where it can beat Ascribe:
If your main bottleneck is “it takes too long to get to a stable codeframe we trust,” Caplena’s approach can be compelling. It’s designed to accelerate early structure-building and make iteration easier.
Tradeoffs to watch:
As with most systems, straightforward, repetitive text is easier than nuanced verbatims. The risk is not that the tool fails, it’s that your hardest comments (multi-issue, subtle, context-dependent) require more analyst effort than expected. Plan for that in your staffing and timelines.
What to test in a pilot:
- Time from raw data to a codeframe you would defend in a readout.
- Analyst effort required to correct and stabilize categories.
- Quality of segmentation outputs and how cleanly exports fit your reporting stack.
4) Thematic
Best for: Teams doing continuous feedback analysis (VoC, product feedback, support tickets) who want dashboards, slicing, and strong drill-down from themes to raw text.
What it is:
Thematic focuses on turning text feedback into themes (often alongside sentiment), with drill-down so teams can connect insights back to verbatims and track patterns over time.
Where it can beat Ascribe:
If stakeholders want always-on reporting, filtering by product/region/channel, and quick drill-down for “what’s driving this,” Thematic’s emphasis on analysis and reporting can be a strong fit.
Tradeoffs to watch:
Thematic is often used as a feedback analytics platform. If your primary need is classic MR open-end coding for survey deliverables (strict codeframes, study-specific nets, client formatting expectations), validate that the workflow supports those outputs, not only dashboards.
What to test in a pilot:
- Whether you can enforce a codebook that matches your study spec.
- Whether exports work cleanly for your quant workflow without heavy transformation.
- Whether you can generate slide-ready charts and quotes, not just an internal dashboard.
5) Forsta (Genius Text Analytics)
Best for: Enterprise programs already invested in the Forsta ecosystem, or teams that need text analytics connected to broader CX and research program infrastructure.
What it is:
Forsta’s text analytics capabilities are typically used to categorize open text and apply sentiment, usually as part of a broader program measurement and reporting setup.
Where it can beat Ascribe:
If your org is standardizing survey operations inside a larger platform, Forsta can be attractive because it fits into broader program workflows (measurement, reporting, operational follow-up), rather than living as a standalone coding tool.
Tradeoffs to watch:
The practical question is setup and iteration: how quickly you get to a stable categorization model that matches your business language, and how flexible it is when questionnaires change or codeframes evolve across waves.
What to test in a pilot:
- Time to first stable categorization workflow.
- How codebook changes are managed across waves.
- Whether you can produce MR-style deliverables on your timeline, not just operational reporting.
How to run a fair pilot (and avoid “AI accuracy” arguments)
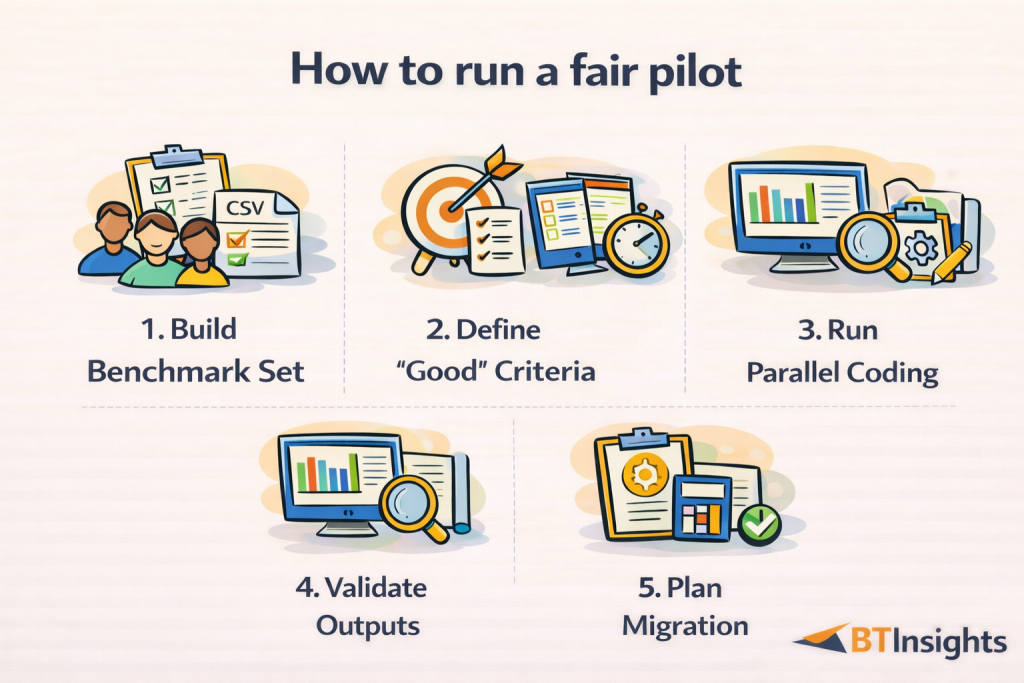
If you want to choose well, do not evaluate on demo data. Evaluate on your worst real data.
Here is a repeatable pilot plan that works for most MR and insights teams.
Step 1: Build a benchmark set
Pull 300 to 800 verbatims from recent projects, across:
Multiple segments (for crosstabs), multiple open-end questions, and at least one language edge case if multilingual matters.
Include “hard mode” responses:
- multi-topic answers (“Price is high but quality is great”)
- negation (“Not bad,” “I wouldn’t say it’s easy”)
- sarcasm or jokes
- vague responses (“Fine,” “Okay”)
- brand and competitor mentions
Step 2: Define what “good” looks like
Decide your scoring, before you run the tools:
- Code coverage (how many responses get a meaningful label)
- Precision on critical themes (the ones that drive decisions)
- Consistency (does it label similar responses similarly)
- Analyst edit burden (minutes to correct outputs, not just quality)
- Output usability (how quickly you can produce the table or slide you need)
Step 3: Run parallel coding
Have your current process and the candidate tool both code the benchmark set.
Do not over-index on agreement percentages alone. A tool that is “less accurate” but dramatically easier to review and correct can win in practice.
Step 4: Validate segmentation and reporting outputs
This is where many pilots fail.
Force the tool to answer:
“What are the top themes among detractors vs promoters?”
“What changed vs last wave?”
“What quotes support the top two drivers?”
If it cannot produce those outputs quickly, it is not the right alternative, even if the coding looks decent.
Step 5: Decide with a migration plan, not just a score
Include:
- how you will map legacy codeframes
- who owns the codebook governance
- how you will maintain consistency across waves
- what outputs you must reproduce (crosstabs, charts, slide templates)
What to include in your open-ends report (so it is decision-ready)
To make your open-ends section decision-ready, end with a one-page executive summary that answers: what changed, what matters, and what we should do next. Then show a ranked theme distribution by percent mention with clear definitions, so themes are measurable, not anecdotal.
Next, include a few essential segment cuts (at minimum: satisfied vs dissatisfied, plus one business-critical segment like region or tier) to prove the story holds for priority groups. Finally, translate the top themes into action: a short “so what,” a likely driver, and a clear owner, backed by a small evidence appendix of representative quotes and a brief QA note on how you coded. Tooling matters most here, because the biggest time savings usually come from faster theme quantification, segmentation, and quote extraction, not just faster initial tagging.
If your team is evaluating Ascribe alternatives because you want faster coding plus decision-ready outputs, start with a benchmark pilot on your real open-ends. If you want to see how an AI-native workflow handles codebooks, review, and reporting, book a demo with BTInsights.
FAQ
How many open-ended responses do I need before I should use a dedicated coding platform?
If you have more than a few hundred verbatims, or you run this monthly, the time savings and consistency gains usually justify a dedicated workflow. The bigger trigger is not volume alone, it is how often you need segmentation and trend reporting.
How do I validate AI-assisted coding quality?
Use a benchmark set, compare against a human-coded reference on critical themes, and measure analyst edit burden. Always test on your messiest responses, not your easiest.
Should I use sentiment analysis for survey open-ends?
Use it as a secondary lens. It helps summarize emotional direction, but themes and drivers usually carry the decision weight. Also confirm whether the tool assigns sentiment at the response level or per topic, because that affects interpretation.
Is custom pricing a problem?
Not necessarily, but it can slow procurement and make comparisons harder. Ascribe Coder is commonly described as having custom pricing, so plan for a structured pilot and a clear requirements doc so pricing aligns to usage.
AI survey open-ends analysis with exceptional accuracy
Let AI generate codes or use your own codebook