
The best survey text analysis tools in 2026 are the ones that match real research workflows: they extract themes fast, support human review and codebook control, and keep every insight traceable back to verbatim responses. The most reliable way to choose is to run a pilot that tests editability, auditability, and report readiness, not just “first pass” AI outputs.
If you are evaluating survey text analysis tools this year, you are probably trying to do two things at once: speed up open-ended coding and still ship something that stands up to scrutiny. The tools all look similar in demos. The differences show up later, when you need to revise codes, compare segments, pull quotes, and build a decision-ready deck.
What survey text analysis means in 2026
Survey text analysis is the process of turning open-ended survey responses into structured outputs you can analyze and report. In practice, that includes theme extraction, coding, frequency counts, sentiment by theme (when relevant), and comparisons across segments.
Open-ended coding is the act of assigning labels (codes) to responses so patterns become measurable. A modern workflow often starts with AI-generated codes or draft themes, but the research-grade version always includes a review loop where humans approve, revise, merge, split, and standardize the codebook.
Traceability is what prevents fragile insights. It means you can click from a theme or summary back to the exact verbatim responses that support it. The practical version is verifiability: every claim is linked to evidence and can be reviewed.
What changed in 2026 and why choosing tools is harder
Tool selection is harder in 2026 because the market looks more “equal” on the surface, but workflows still break in predictable places.
AI features are everywhere
Most survey, CX, and analytics platforms claim some form of “AI insights.” The real difference is not whether AI exists. It is whether you can review, edit, and verify what the AI produced. If you cannot click from an insight to the exact responses and quotes behind it, you cannot defend the output.
Faster turnaround is the new baseline
Stakeholders increasingly expect decision-ready readouts in hours, not days. Tools that stop at theme lists create extra work because you still have to build the core outputs that matter: code distributions, segment cuts, crosstabs, and slide-ready reporting. If those are manual, you lose most of the time you thought you saved.
Risk tolerance is lower
Leadership is more aware that AI-generated summaries can sound confident while being incomplete or wrong. Practically, that means traceability to raw responses, clear review workflows, and an audit trail you can explain when someone asks, “How did we get this conclusion?”
The selection criteria that actually predict success

Most evaluation checklists overemphasize surface features. The criteria below predict whether your team will still like the tool after the second or third study.
Traceability and evidence quality
A good tool makes it trivial to answer, “Where did this insight come from?” You want to move from theme to supporting responses without friction. The best experiences make evidence feel “attached” to insights, so quoting and validation become fast rather than tedious.
Human-in-the-loop review and codebook control
If you cannot edit codes comfortably, you cannot scale reliably. Look for workflows that let you merge and split codes, rewrite definitions, apply inclusion rules, and re-run or re-apply coding without turning the project into a rebuild. This matters even more for trackers, where you need consistency over time.
Segmenting and quant outputs that match research needs
Open-ends are often most useful when you can answer “who is saying this?” Segment analysis and crosstabs are not optional for most market research teams. A tool that can code text but cannot connect those codes to segments, distributions, and comparisons forces you into spreadsheets and manual analysis.
Reporting readiness
A platform can be strong at analysis and still fail at delivery. If your end product is a client deck, the tool needs to help you ship a deck. That can mean PowerPoint exports, chart outputs that paste cleanly, reusable templates, and quote-backed slides that preserve evidence.
Collaboration and governance
Research is rarely a solo activity. You will get better outcomes when the tool supports reviewer workflows, permissions, version history, and a clear audit trail. That matters when stakeholders ask “how did we code this?” or when a team needs to replicate the approach next quarter.
Multilingual consistency and entity handling
If you work across regions, multilingual support becomes a reliability issue, not a nice-to-have. Look for consistent labeling across languages and the ability to code entities when needed, such as competitor mentions, product features, or brand references.
How to choose the best survey text analysis tools in 2026
This is a simple, repeatable selection process that research teams can run in a week without over-engineering.
Start with your real deliverable, not the tool category
Before looking at vendors, write down what “done” looks like. If your deliverable is a deck with top themes, supporting quotes, and segment cuts, that should drive your selection more than whether a tool calls itself “text analytics” or “AI survey insights.”
Also define what you are optimizing for. Some teams are optimizing for speed on high-volume studies. Others are optimizing for control and consistency across waves. These are different needs and they lead to different best-fit tools.
Build a pilot dataset that exposes workflow weaknesses
Pilots often fail because the dataset is too clean. Use a realistic sample, ideally 300 to 1,000 responses, with variation in length and clarity. Include at least three segments you care about, such as region, customer tier, or NPS group. If you have multilingual requirements, include at least two languages in the pilot, because this is where many tools look good in a demo and struggle in reality.
Decide your coding approach up front
You will get better evaluation results if you choose a consistent approach across tools. Most teams pick one of three patterns.
AI-generated codes with human review is common when you need discovery and speed. The success factor is how easy it is to curate and stabilize the codebook.
Codebook-first, AI-assisted application is common for tracking studies. The success factor is how well the tool applies your codes consistently and how it handles edge cases.
Hybrid approaches are common in practice. AI proposes, researchers curate, then the curated codebook becomes the standard for that project or tracker.
Score tools on criteria that map to real work
Instead of asking “does it have feature X,” ask “how fast can we do task Y?” Task-based scoring exposes real differences. Good tasks to test are: editing and re-running codes, pulling quotes for a theme, producing a theme-by-segment view, and exporting a clean slide.
Force a “second pass” test
A tool that performs well on first-pass themes can collapse when you try to refine the output. In your pilot, require one round of edits and a rerun or re-application. This is where you find out if the workflow is research-grade or just a demo experience.
Test the last mile: reporting and stakeholder readiness
A tool should help you ship the output stakeholders want. Create one “gold standard” slide you always have to deliver, then see how quickly each tool can produce it with evidence. If the tool cannot support that last mile, the team ends up doing manual work that erases most of the time saved in analysis.
Best Survey Text Analysis Tools in 2026
In 2026, the “best” survey text analysis tool is the one that fits real research work: fast theme extraction, human review and codebook control, traceability to verbatims, and reporting-ready outputs. Here are the tools most teams evaluate.
BTInsights: Best overall for research-grade open-ended coding
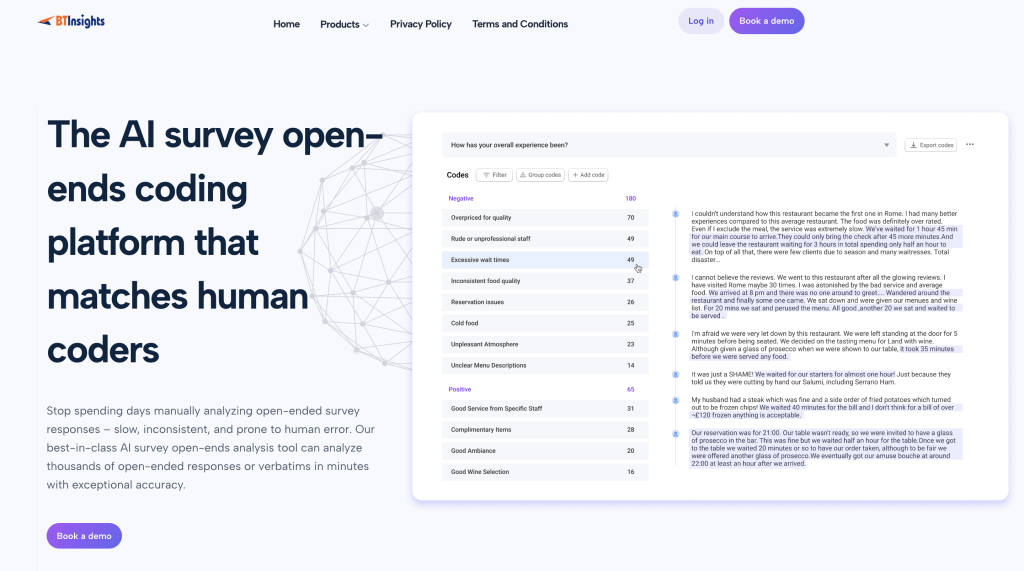
BTInsights is purpose-built for market research and insights teams that need to code open-ended responses at scale, while keeping accuracy that matches human coders and outputs that stand up to scrutiny.
Why it stands out
- Built for market researchers: The workflow is designed for research-grade coding, not generic text summarization.
- Human-in-the-loop: AI drafts themes and codes fast, then researchers review, edit, and finalize what counts.
Verifiability over “trust me” AI
- No AI hallucinations (via traceability): Every theme and insight is linked back to the original verbatims, so teams can validate and challenge results before reporting.
- Defensible outputs: Clear audit trail from raw text to codes, themes, and summaries.
Flexible coding options
- AI-generated codes or your codebook: Start with AI suggestions for discovery, or apply an existing codebook for consistency and tracking.
- Entity coding: Capture brands, products, competitors, people, and locations systematically, alongside themes.
Best fit when
- You need speed at scale without losing accuracy.
- You want humans to control the final codebook through review and editing.
- You are coding across 50+ languages and need outputs in those same languages.
- You need quote-backed themes, distributions, and segment cuts that are ready for reporting.
AI survey open-ends analysis with exceptional accuracy
Let AI generate codes or use your own codebook
Displayr
Displayr is widely used for survey analytics and reporting, especially when teams want quant analysis and presentation outputs in one environment. It can work well when your main priority is the quant pipeline and text is an input to the overall story.
- Strength: Strong for quant analysis and producing reporting outputs within a single workflow.
- Where it can fit: When your primary pain is analysis + deck production, and your team is comfortable structuring text workflows inside a quant-led reporting process.
Best fit when:
- Your team is already invested in Displayr for quant reporting.
- You want text analysis to feed the broader reporting pipeline.
Qualtrics Text iQ
Qualtrics Text iQ is commonly evaluated by teams that already use Qualtrics as their survey system of record. Its biggest advantage is operational convenience: fewer handoffs and less data movement.
- Strength: Tight integration if Qualtrics is already your core survey platform.
- Where it can fit: When speed and simplicity matter and you want analysis close to collection.
Best fit when:
- You prioritize staying inside the Qualtrics ecosystem.
- Your text workflow needs are moderate and you value operational simplicity.
Dovetail
Dovetail is best known for qualitative synthesis and evidence management across interviews, notes, and mixed qualitative sources. For survey open-ends, it can be useful when your goal is qualitative narrative and evidence capture more than quant-style reporting.
- Strength: Strong for qualitative synthesis, tagging, and evidence retrieval across studies.
- Where it can fit: When survey open-ends are part of broader qualitative work and your output is more narrative and insight synthesis driven.
Best fit when:
- You need cross-study qualitative synthesis and strong evidence management.
- Your deliverable is more “insight narrative” than “survey crosstabs + deck automation.”
NVivo

NVivo is a long-standing qualitative analysis tool built for deep, manual coding and detailed qualitative work. It offers high control and rigor when teams want granular coding structures and are comfortable with traditional qualitative workflows.
- Strength: Deep control for manual coding and structured qualitative analysis.
- Where it can fit: When depth and coding rigor matter more than fast-turn reporting.
Best fit when:
- You prioritize qualitative depth and control.
- Your workflow can tolerate more manual effort and less automation.
Tool Comparison Snapshot: Traceability, Review, Reporting, and Segments
Below is a high-level comparison based on research workflow fit. Your pilot should determine what “strong” means for your organization.
| Tool | Best for | Traceability to quotes | Human review workflow | Segment analysis and crosstabs | Reporting outputs (PPT/report) | Notes for research teams |
| BTInsights | Research-grade open-ended coding and reporting | Strong | Strong | Strong | Strong | Built for theme extraction, code review and editing, and quote-backed reporting. It supports verifiable analysis in practice by tying every insight back to the underlying responses. |
| Displayr | Quant analysis plus reporting pipelines | Medium | Medium | Strong | Strong | Often strong for survey analytics and reporting; validate text workflow depth and evidence traceability. |
| Qualtrics Text iQ | Teams already on Qualtrics | Medium | Medium | Medium | Medium | Convenient in-stack option; validate flexibility for codebook control, reruns, and reporting needs. |
| Dovetail | Qual synthesis and evidence management | Strong | Strong | Weak–Medium | Medium | Great for qualitative storytelling and cross-study synthesis; validate quant survey outputs and speed-to-deck. |
| NVivo | Deep qualitative control | Medium | Strong | Weak | Weak–Medium | Powerful manual coding; can be heavier for high-volume survey open-ends and automation. |
What “best” means depending on your team
For market research teams shipping decks weekly
If you regularly deliver client-ready outputs on deadlines, “best” tends to mean end-to-end speed without losing defensibility. You want a tool that can draft themes quickly, let researchers refine and lock the codebook, produce segment cuts, and generate reporting outputs without a fragile handoff between tools. In that world, platforms designed around research workflows tend to outperform generic text analytics because they reduce workflow friction and preserve evidence.
For insights teams doing synthesis across many sources
If your work blends surveys with in-depth interviews, focus groups, and other qualitative sources, “best” often means evidence management and synthesis. Quote retrieval and traceability can matter even more than crosstabs. You may still need quant summaries for surveys, but the differentiator is often how well the tool supports consistent tagging and cross-study learning.
For ops or engineering-led organizations
If you have strong technical resources and want integration into internal systems, “best” might be a pipeline approach. The evaluation should be honest about what you will need to build to reach research-grade standards, particularly review workflows and evidence traceability. Without those, the organization can move fast but struggle to defend conclusions.
How to make sure the tool is reliable enough to use
Choosing a tool is not only about features. It is about whether you can validate outputs quickly.
Audit a stratified sample
Pull a sample across segments and response lengths, then check whether codes match meaning. The point is not to catch every edge case. The point is to detect systematic problems, such as overly broad themes, missing critical issues, or inconsistent labeling across segments.
Review negative cases
For each top theme, look for responses that appear close but do not belong. This helps prevent the common failure mode where the tool produces a summary that sounds plausible but glosses over important nuance.
Check stability after codebook edits
If you merge two codes, split a code into subthemes, or tighten a definition, does the tool preserve traceability and keep the workflow clean? This is one of the strongest indicators of whether a platform is built for research-grade work.
Validate segment differences explicitly
Stakeholders often act on segment differences more than overall counts. If a theme appears “high” in one segment, confirm the quotes and the coding logic in that segment. Tools that make it easy to click into segment-specific evidence reduce the risk of overclaiming.
Require evidence for every headline
For every slide headline you plan to present, require a minimum evidence standard: supporting quotes, response counts, and segment visibility. This is the practical version of minimizing hallucination risk. You are not trusting AI. You are using AI within a workflow where every insight can be verified.
What to include in a decision-ready deliverable
A strong survey text analysis readout follows a simple structure because stakeholders want consistent answers.
Start with a tight theme summary that highlights the few patterns that matter. Then back each theme with evidence, usually two to four representative quotes, so the audience can see exactly what respondents said. Add quantification to prioritize, like theme frequency and sentiment where it helps interpretation.
Next, show the segment cut, because most decisions depend on who is driving an issue, not just whether it exists. Close with implications: what to fix, test, message, and measure next, plus a short methods note if you used AI-assisted coding to make the process auditable.
FAQ: Choosing the best survey text analysis tools in 2026
What is the fastest way to shortlist tools?
Start with your deliverable and constraints, then shortlist tools that clearly support traceability, review workflows, segment analysis, and exportable reporting. Avoid evaluating tools that cannot show evidence behind insights.
Should I use AI-generated codes or a predefined codebook?
AI-generated codes are useful for discovery and speed. A predefined codebook is useful for consistency and tracking. Many teams use AI to propose codes, then finalize a curated codebook and reuse it for the rest of the study or future waves.
How do I reduce the risk of wrong summaries?
Use a workflow that requires evidence for claims. Validate on a stratified sample, review negative cases, and insist on traceability to verbatims for every reported theme. The goal is to make outputs verifiable, not to assume accuracy.
Can qualitative platforms replace survey text analysis tools?
They can for certain deliverables, especially narrative synthesis and evidence capture. If you need crosstabs, segment distributions, and fast slide production, validate whether the workflow supports that without heavy manual work.
Is spreadsheet coding still viable in 2026?
It can work for small datasets, but it becomes slow and hard to QA at scale. It is also harder to maintain traceability and consistent coding across researchers without strict processes.
AI survey open-ends analysis with exceptional accuracy
Let AI generate codes or use your own codebook