
Qualtrics Text iQ is a common default when you already field surveys in Qualtrics, and you need a quick way to bring structure to open-ended responses. The problem is that “structure” is not the same as “decision-ready insight”.
If your workflow involves building a defensible codeframe, validating themes, quantifying what changed by segment, and then shipping a deck your stakeholders can act on, you may start to feel constrained.
This guide covers seven strong alternatives to Qualtrics Text iQ in 2026, with a research-grade selection checklist you can reuse across projects.
It’s intentionally scoped to text analysis. This is not a “Qualtrics replacement” article for survey programming, distribution, panels, or enterprise XM stacks.
What Text iQ is good for, and where teams hit friction
Text iQ is typically used to turn open text into topics and sentiment so teams can scan patterns across large datasets. That’s useful when your main goal is triage.
Teams tend to look elsewhere when they need one or more of the following:
First, codeframes that match the study. When you have a specific research question (for example, “What drives churn risk for SMB customers?”), generic taxonomies can create noise, or force you into heavy rework.
Second, traceability. Stakeholders trust insights more when every theme is backed by verbatims you can pull instantly, with clear rules for what got coded where.
Third, faster delivery. If you still spend hours rebuilding tags, handling “no code” responses, and stitching evidence into slides, the automation did not really remove the bottleneck.
How to evaluate Qualtrics Text iQ alternatives
Before you compare vendors, decide what “better” means for your team. A CX team doing daily triage has different needs than an MR team producing a quarterly tracker readout.
Use this checklist in a pilot, on your own dataset.
Codeframe control and reuse
You want to control the structure, not just accept whatever the model generates.
Look for how the tool handles hierarchical themes, merging and splitting codes, multi-label coding, and whether you can reuse a codeframe across waves without losing comparability. If you do tracking, this is non-negotiable.
Validation and reliability workflow
If you cannot QA efficiently, you will not trust the output, and your stakeholders will learn not to trust it either.
In practice, that means: quick sampling, easy recoding, clear “no code” handling, and an audit trail for what changed and why. If multiple people code, check whether the tool supports lightweight agreement checks.
Quant outputs that actually map to MR reporting
Themes are only half the job. You need quant summaries you can defend.
At minimum: code counts and distributions, base sizes, and the ability to break results by segment (demographics, customer tier, market, wave). If you regularly report on movement, you need trend comparisons that do not require a spreadsheet rescue mission.
Evidence and deliverables
Research is persuasion backed by data. Your workflow needs proof.
Look for fast quote extraction, the ability to keep quotes attached to themes as evidence, and exports that match how you build deliverables (tables you can paste, spreadsheets you can crosstab, or report outputs you can adapt).
Practical fit with Qualtrics
Most teams keep Qualtrics for collection, then improve analysis downstream.
So evaluate how the tool handles imports from Qualtrics exports, how it supports collaboration, and whether permissions and review flows match your organization’s expectations.
The 7 best Qualtrics Text iQ text analysis alternatives in 2026
The list below spans three categories because “text analysis” serves different workflows: research-grade coding, VoC and CX intelligence, and deep qualitative analysis. The right choice depends on the decision you’re trying to support.
1) BTInsights – the overall best alternative for Qualtrics Text iQ
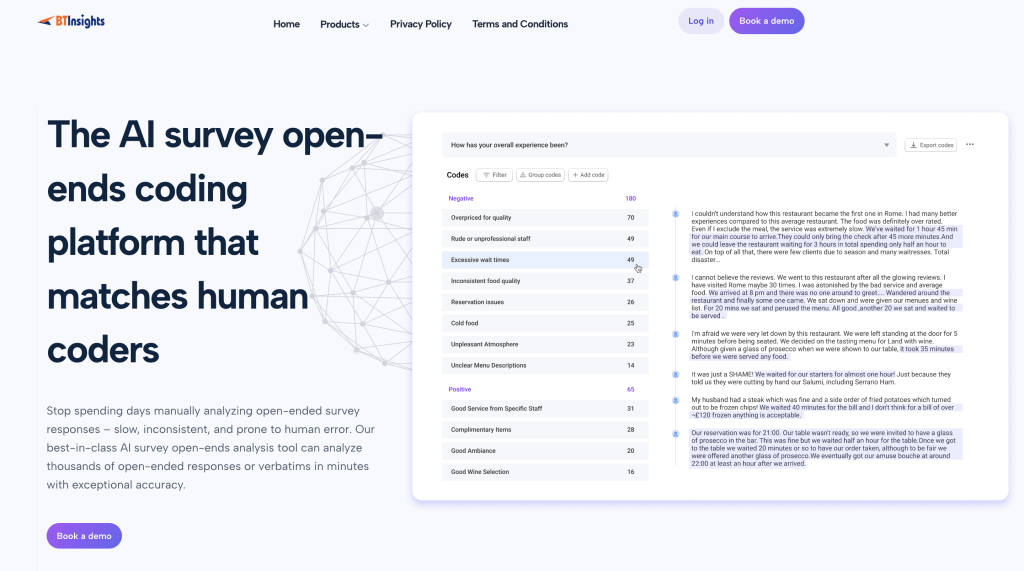
Best for: market research and insights teams who need clear themes plus traceable evidence, fast, across open-ended surveys and qualitative transcripts. Best fit when you need consistent themes, supporting quotes, and a reviewable workflow. BTInsights is designed for that.
BTInsights is a leading choice for research teams because it is built specifically for market research workflows, not generic “text analytics.” It helps you surface clear themes from interviews and focus groups, then quickly pull supporting quotes from transcripts so every insight stays tied to evidence. For open-ended survey responses, BTInsights can code verbatims into a structured set of themes and show sentiment distribution by code (positive, neutral, negative), which makes it easier to quantify what is changing and why.
The practical advantage for a Text iQ switcher is end-to-end workflow. You want to move from raw verbatims to a clean, defensible set of themes, then to decision-ready outputs with an audit trail you can stand behind. BTInsights is designed for speed at scale and includes review and edit workflows, so analysts can validate edge cases quickly and keep control of the codeframe, instead of accepting outputs blindly.
If your organization already collects in Qualtrics, BTInsights can fit as the analysis layer: export open-ends, code and validate themes, then reuse the same narrative structure across waves.
AI survey open-ends analysis with exceptional accuracy
Let AI generate codes or use your own codebook
2) Thematic
Best for: teams that want a dedicated feedback analysis product, especially when they connect multiple data sources.
Thematic positions itself as specializing in feedback analysis rather than survey building, and it highlights integrations across channels. It also explicitly mentions a native Qualtrics integration, which matters if you want to keep collection in Qualtrics and improve analysis elsewhere.
This category of tool can be a strong fit when you need a repeatable theme model you can apply across ongoing feedback streams, not just one-off studies. It can be less ideal when your workflow is highly study-specific and you need tight control over a custom codeframe for a single research question.
3) Chattermill
Best for: customer experience and product teams who need multi-source VoC intelligence, not just survey open-ends.
Many “Text iQ alternative” lists include Chattermill because it covers omnichannel text, themes, and operational workflows. In CX settings, that matters because insight is often tied to action, prioritization, and closing the loop.
Choose this type of tool when your stakeholders care about “what should we fix this week” and you need fast dashboards and issue tracking. If you are doing classic market research deliverables, you will want to ensure you can still export clean tables, segment splits, and evidence for a presentation.
4) Enterpret
Best for: product, support, and research teams consolidating large volumes of feedback into a unified taxonomy.
Enterpret commonly shows up in Text iQ alternative roundups because it is built around unifying feedback sources and turning them into structured themes that teams can query and monitor.
This category can be a good fit when your problem is fragmentation: NPS verbatims in one tool, support tickets in another, app store reviews in a third. It can be a weaker fit when your research requires a very specific codebook and formal QA steps that are closer to traditional MR coding.
5) Netigate
Best for: CX teams that want a quick path from text to themes, with a focus on operational insight.
Netigate fits teams running ongoing experience programs who need to summarize large volumes of feedback and monitor themes over time.
The main decision point here is whether your workflow is more like experience monitoring or more like research reporting. If you live in dashboards and need quick summaries, this category can be strong. If you live in decks and need rigorous evidence and segment-by-segment interpretation, validate the exports and traceability before committing.
6) NVivo

Best for: rigorous qualitative analysis when depth matters more than speed.
NVivo remains a go-to in academic and qualitative research contexts because it supports deep, hands-on coding across multiple formats. In many teams, NVivo becomes the “methodological backbone” for projects where you need defensible coding decisions and detailed interpretation.
The tradeoff is speed and effort. NVivo is often manual and can be heavier to operate for large volumes of survey verbatims. If you choose NVivo as your Text iQ alternative, treat it as a rigor-first option, not a speed-first one.
7) Ascribe
Best for: traditional manual coding teams who want full control and already have established coding standards.
Ascribe is frequently described as a long-standing option for line-by-line manual coding, preferred by teams that want tight control over how themes are defined and refined.
If you have a dedicated coding team and a formal codebook culture, Ascribe can be a stable choice. The tradeoff is turnaround time, especially as volumes increase.
How to choose the right alternative in practice
Here’s a simple decision logic you can reuse.
If your primary output is a report or PPT
Prioritize tools such as BTInsights that make it easy to: (1) define themes clearly, (2) pull supporting quotes instantly, and (3) quantify patterns by segment.
Before you buy, run a pilot on one real dataset and verify you can answer three stakeholder questions quickly:
What changed?
Why did it change?
What should we do next?
If your primary output is an operational dashboard
Prioritize multi-source ingestion, trend monitoring, and workflow features for routing issues and closing the loop.
Your pilot should test whether the tool helps teams act faster, not just whether it produces a nicer word cloud.
If your primary output is methodological rigor
Prioritize codebook support, traceable coding decisions, and the ability to handle complex qualitative data.
Your pilot should test whether the tool supports consistent coding across coders and whether you can defend choices in an appendix.
AI survey open-ends analysis with exceptional accuracy
Let AI generate codes or use your own codebook
A reliable open-ended coding workflow you can reuse (regardless of tool)
Most “bad AI coding” outcomes are actually “bad workflow” outcomes. Here’s a lightweight process that keeps outputs defensible.
Step 1: Define the decision the research must support
Write the decision in one sentence. Example: “Decide whether shipping speed or price messaging should be the main lever for improving repeat purchase.”
This keeps your codeframe from drifting into a list of random topics.
Step 2: Build an initial codeframe from a stratified sample
Pull a sample that reflects your segmentation. If you have three key customer tiers, sample across all three.
Create a first-pass codeframe that includes drivers, not just categories. “Shipping” is a bucket. “Shipping arrived later than promised” is a driver.
Step 3: Code, then run an explicit QA pass
Do not skip this.
Review the highest-frequency codes and the most ambiguous codes. Look for these failure patterns: mixed sentiment, sarcasm, short answers, and responses that belong to multiple themes.
When you edit the codeframe, track what changed. A simple change log becomes a lifesaver in wave-to-wave tracking.
Step 4: Quantify the story, not just the themes
Move from “what people said” to “how often it shows up, and where.”
A practical structure is: overall distribution, then top differences by segment, then any emerging themes that explain movement in a KPI.
Example: In Q2, “delivery arrived late” rises from 9% to 16% among first-time buyers. The driver is not just speed, it’s expectation setting. The quotes mention “said 2 days, arrived in 5” and “no tracking updates.”
Action: adjust delivery promise language for the first-time buyer flow and improve tracking notifications. Validate in the next wave by checking whether that theme drops and whether repeat purchase lifts.
Step 5: Extract evidence for each key point
For every headline insight, pull 3 to 5 quotes that represent it, and 1 quote that challenges it.
That last quote helps you avoid overfitting to the loudest pattern.
Step 6: Ship deliverables with traceability
Your stakeholders want clarity, not a data dump.
A strong deck flow is: objective, what changed, what’s driving it, who it impacts, what to do next, and a short method and QA appendix.
Pitfalls to address, and how to validate against them
Mixed sentiment is the most common failure mode in real-world verbatims. “Love the product, hate the shipping” should not be flattened into a single label. Validate by sampling mixed-sentiment responses and checking whether the tool supports multi-label coding.
Negation and sarcasm are traps for keyword-driven approaches. Validate by searching for phrases like “not great,” “could be worse,” or sarcastic constructions, then checking where they land.
Short answers and vague prompts (“Any other comments?”) create a high “no code” share. Track “no code” explicitly and decide whether to treat it as noise or a sign that your question design needs improvement.
Segment language drift can break comparability. A theme called “pricing” can mean “too expensive” in one segment and “confusing tiers” in another. Validate by reading top quotes per segment, not just overall frequency.
What to include in your report so stakeholders trust the results
A decision-ready output usually includes theme definitions (plain language), a quant summary (overall and by segment), a short set of drivers (why it’s happening), and actions (what to do next), with evidence quotes embedded near each claim.
Add a short QA note. Explain how you sampled, what you checked, and how you handled ambiguous cases. This is often the difference between “interesting” and “trusted.”
If you want a faster way to code open-ended survey responses, validate themes, and pull evidence-backed quotes into reports, book a demo of BTInsights.
FAQ
Are Qualtrics Text iQ alternatives only for CX teams?
No. Many alternatives are built for CX, but several are strong for market research workflows too. The key is whether they support codeframe control, segment quantification, and report-ready evidence.
Can I use a Text iQ alternative without leaving Qualtrics?
Often, yes. Many teams keep survey fielding in Qualtrics and export open-ends for analysis elsewhere. Some tools also highlight Qualtrics integrations, which can reduce friction.
What matters more: sentiment accuracy or coding transparency?
For decision-making, transparency usually wins. If you cannot explain why something was tagged, you will struggle to defend conclusions. Sentiment is useful, but only when it aligns with clear theme definitions and evidence.
How do I validate that my themes are reliable?
Use a stratified sample, review ambiguous categories, check edge cases, and keep a change log of codeframe edits. If multiple coders are involved, compare a subset and resolve disagreements explicitly.
What should I do with “no code” responses?
Treat them as information. A high “no code” share can indicate vague question wording, poor codeframe coverage, or a segment with distinct language. Track it and diagnose the cause.
Should I choose a VoC platform or a qualitative analysis tool?
Choose based on your primary output. If you need dashboards and issue management, a VoC platform can fit. If you need defensible coding and research deliverables, favor research-grade analysis workflows.
Is manual coding still worth it in 2026?
Sometimes. Manual tools can be the right choice when rigor is the priority, the dataset is manageable, and you need full analyst control. The cost is turnaround time and scalability.
AI survey open-ends analysis with exceptional accuracy
Let AI generate codes or use your own codebook