
Market researchers are already using ChatGPT. The real question is whether they are using it in a way that holds up when results are reviewed, challenged, or reused in the next wave.
ChatGPT can meaningfully increase efficiency in market research, especially when the work is text-heavy and the goal is to move faster from messy inputs to a clear next step. But general-purpose chatbots also have predictable failure modes in research workflows: hallucinations as the volume grows, weak traceability from insight back to evidence, and unreliable quantification for themes and reporting outputs.
This guide shows a practical way to use ChatGPT that improves speed without lowering standards. The “right way” is not a magical prompt. It is a workflow: constrain inputs, lock definitions, validate on samples, keep evidence attached, and treat the model as an assistant inside an auditable process.
What ChatGPT is actually good at in market research

The best uses of ChatGPT are the ones where a small amount of error does not silently corrupt your decision. In other words, use it to accelerate preparation, structure, and drafting. Be more cautious when the output will be treated as measurement.
Desk research synthesis and background structure
ChatGPT is useful for quickly turning scattered background material into a structured view. If you paste in notes from internal docs, transcripts from stakeholder interviews, or summaries of what you already know, it can propose a clean outline: market context, major competitors, common buyer objections, likely decision criteria, and hypotheses worth validating.
The key is to treat this as hypothesis generation and organization, not as “facts.” ChatGPT can help you produce a first version of a landscape summary and a list of questions you still need to answer with primary research.
Drafting research instruments
ChatGPT can speed up the early drafting of research instruments, especially when you already know what you are trying to learn. It can propose screener questions, discussion guide sections, and follow-up probes. It can also rewrite questions to reduce ambiguity, balance wording, and make response options mutually exclusive.
This is a strong efficiency gain because instrument drafting is often iterative and language-sensitive. ChatGPT can generate variants quickly, then you choose and edit.
Creating a first-pass qualitative structure
If you have a small sample of open-ended responses or a few transcript excerpts, ChatGPT can propose an initial codebook. That might include theme names, simple definitions, and suggested sub-themes. It can also highlight recurring phrases and potential “buckets” you may want to look for as you code more data.
This works best on a small and clearly defined sample. The goal is not to finalize the codebook, it is to get to a reasonable starting structure faster.
Rewriting raw inputs into clearer language
Researchers spend a lot of time turning raw material into something stakeholders can read. ChatGPT can rewrite messy notes into clean summaries, translate jargon into stakeholder-friendly language, and turn a rough insight into a clear statement with scope and qualifiers.
This can be especially helpful for building a consistent narrative voice across a report, as long as you preserve the meaning and keep evidence attached.
The right way workflow: use ChatGPT without breaking research rigor
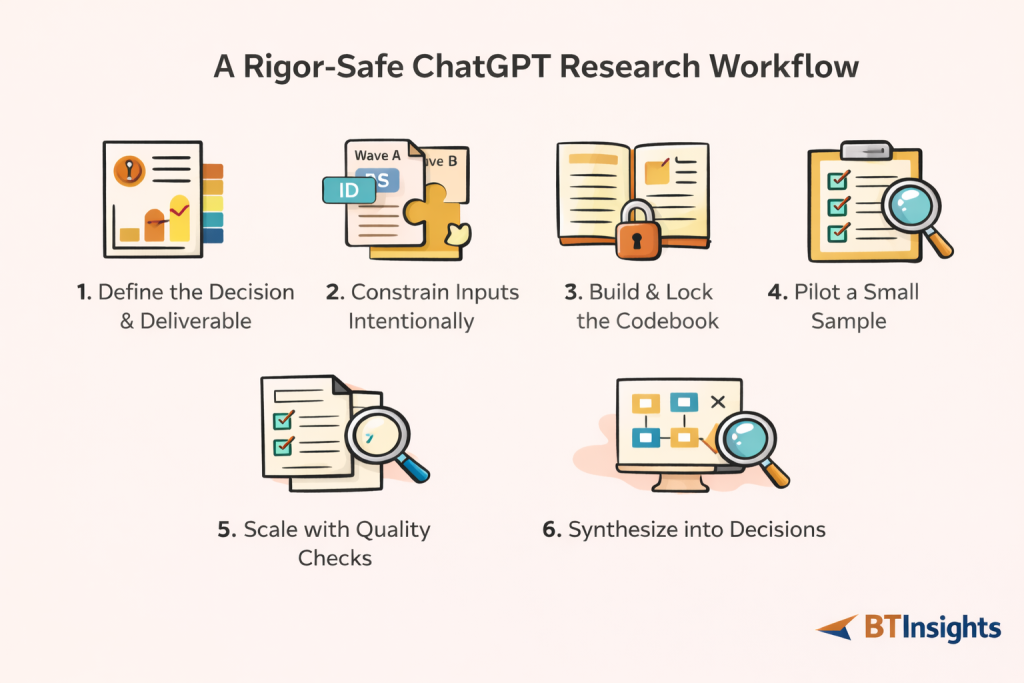
If you want outputs that are decision-ready, the workflow matters more than the prompts. The steps below are designed to reduce the most common errors researchers see from general AI tools: confident fabrication, inconsistent interpretation, and untraceable conclusions.
Step 1: Start with the decision and the deliverable
Before you involve ChatGPT, define what “useful” looks like.
What decision is this research meant to inform. What will change if the finding is true. Kinds of deliverables must you produce, and in what format: themes, quantified theme distribution, segment comparisons, a top-line narrative, or an executive deck.
This step prevents a common failure mode where the model generates a summary that sounds polished but is not shaped around a real decision. It also clarifies what should be treated as qualitative narrative versus what must be measured and audited.
Step 2: Constrain your inputs intentionally
General chatbots perform better when the problem is bounded. Market research data often is not. The temptation is to paste a large amount of text and ask for “insights.” That increases hallucination risk and reduces traceability.
Instead, define the scope of what you want analyzed. Choose a single question, wave, segment, or topic area. Preserve metadata wherever possible. Even simple identifiers like respondent ID and segment label make later validation dramatically easier.
If your dataset is large, process it in batches and keep batch identifiers consistent. The goal is not to “fit everything in.” The goal is to keep the analysis auditable.
Step 3: Build a codebook and lock it
If you are analyzing open-ended responses or transcripts, invest in a codebook early. ChatGPT can help draft one, but you should own the final definitions.
A useful codebook includes a theme name, a clear definition, and boundaries. Boundaries matter because they prevent theme drift. If a theme is “Price concerns,” does it include comments about value, discounts, or competitor pricing. If a theme is “Ease of use,” does it include onboarding, UI navigation, setup time, or documentation.
When the codebook is locked, you can use it as a constraint for later steps. This is a practical way to reduce “creative interpretation” by the model and keep results consistent across batches and waves.
Step 4: Run a pilot on a small sample
Before scaling, run a pilot. This is the easiest and most reliable way to catch misalignment early.
Use a small sample of open-ended responses or a few interviews. Apply the draft codebook. Then review. Where do codes overlap. Which themes are too broad. Which are too narrow. If responses do not fit anywhere. Which responses contain multiple topics that need multi-coding.
Refine the codebook based on what you see, not on what sounds good in a summary. When the pilot looks stable, then scale.
Step 5: Scale with QA, not blind trust
Scaling is where general chatbots most often fail in market research. Even if outputs look plausible, small inconsistencies become large distortions when multiplied across hundreds or thousands of responses.
As you scale, treat the model’s output as a first pass that must be checked. Review a subset from every batch. Pay special attention to the edge cases that models routinely mishandle: sarcasm, negation, mixed sentiment, and responses that mention multiple products or concepts.
Keep a record of codebook changes. If you change a definition, note it and consider whether earlier batches need to be rechecked. Consistency is what makes trend comparisons meaningful over time.
Step 6: Synthesize into decisions, with evidence attached
Synthesis is where your work becomes useful to stakeholders. It is also where untraceable “insights” become risky.
A strong synthesis ties together what is happening, why it is happening, and what to do next. But every claim should remain connected to evidence. If the finding is “Onboarding is the biggest friction point,” you should be able to point to the quotes that support it, the segments where it is concentrated, and the scope of the claim.
Treat the model as a drafting assistant. Let it help you create cleaner phrasing and structure. Keep the truth anchored in the data.
The AI Copilot for interview and survey analysis
Focus Groups – In-Depth Interviews – Surveys
Where general AI chatbots break for market research

Your workflow will be more effective if you understand the failure modes upfront. Most issues researchers face are not random. They are structural.
Weakness 1: hallucination increases as the input gets larger
Hallucination is not just “making up a fact.” In market research it often looks like subtle invention: a theme that was not really present, an exaggerated prevalence, or a causal explanation that was never stated.
Large amounts of information make this worse. When you ask for “the main themes” across a big corpus, the model is forced to generalize and compress. The output can sound coherent even when it is not grounded.
The practical fix is to reduce ambiguity. Constrain the scope, process in batches, and require evidence. Ask the model to provide claims only when it can provide supporting quotes and identifiers. If it cannot, it should say so.
Weakness 2: insights are difficult to trace back to evidence
Stakeholders often ask two questions: “How do we know,” and “Where did that come from.”
General chatbots are not designed for traceability. They generate language, not audit trails. If you are not careful, you end up with a report full of statements you cannot defend in a meeting, because you cannot quickly tie each insight back to the verbatims and segments that support it.
The fix is to build traceability into the workflow. Keep respondent IDs. Require quote excerpts. Keep an “insight to evidence” table as you work. Use the model to help draft summaries, but not to replace the evidence chain.
Weakness 3: quantifying themes and generating reporting outputs is unreliable
Researchers often try to use ChatGPT to quantify themes, produce crosstabs, or generate numbers for reporting. This is where trust breaks quickly.
A general chatbot can miscount, double-count, lose track of totals, or produce inconsistent numbers across reruns. It can also generate slide-friendly outputs that look polished but include numerical claims that are not reconciled to the underlying data.
The fix is to treat the model as a text assistant, not as your counting engine. Use it to propose codes and to label responses, then quantify using auditable methods. If your deliverable requires numbers, you should be able to reconcile them, repeat them, and explain how they were derived.
When purpose-built tools make sense, without making it salesy
ChatGPT can be useful, especially early in the process. But if you are working at scale or need stakeholder-ready traceability, you will often hit limits that are not easily solved by better prompts.
When you need structured qualitative analysis across many interviews or large volumes of open-ended responses, purpose-built tools can be a better fit because the workflow is designed around evidence, review, and reuse. For example, more and more market researchers are using BTInsights to help surface themes from interviews and focus groups and make it easy to pull supporting quotes from transcripts. For open-ended survey responses, BTInsights’ survey coding solution has also become the top choice for market researchers. It can support coding into themes and show how sentiment distributes across codes in a way that is designed for review and editing rather than one-shot generation.
When your biggest pain is turning analysis into consistent reporting outputs, tools that focus specifically on slide and report automation can reduce formatting churn and repetition. PerfectSlide is the newest AI innovation in the survey analysis space. It helps market researchers quickly create survey cross-tab tables and generate PowerPoint slides in their exact format so that they could get the survey analysis and reporting done in minutes or hours instead of days or weeks.
The decision rule is simple. If you are doing small-sample exploratory work, general chatbots can help a lot. If you need reliability, traceability, and repeatable deliverables across large volumes, purpose-built workflows start to matter.
Validation checklist: how to QA AI-assisted research
Validation does not need to be complicated, but it does need to be explicit.
Start by defining what “done” means for your analysis, then run a pilot before scaling. As you scale, review a subset from every batch and pay attention to edge cases where interpretation is fragile. Require evidence for every insight. Keep a clear record of any codebook revisions. Reconcile any quantitative outputs using auditable methods, and never publish numbers you cannot reproduce.
This is what protects your credibility when results are questioned, and it is what makes AI speed-ups safe.
What to include in a decision-ready research report
A decision-ready report does not try to say everything. It prioritizes what matters and shows its work.
Start with a short executive summary that highlights the few insights that actually change decisions. Then present the themes in a ranked way, making clear what is prevalent, what is driving it, and which segments it affects. Keep evidence close to the claims, using verbatims that demonstrate the point without cherry-picking. Close with recommendations that follow from the findings, and define what you would test next if you had another cycle.
If the work involves coding, include the codebook and a short note on your QA approach. Stakeholders may not read it, but your team will benefit later, especially when comparing results across waves.
FAQ
Can ChatGPT analyze open-ended survey responses accurately?
ChatGPT can be useful for first-pass qualitative analysis, especially for labeling responses, suggesting draft codebooks, and surfacing potential themes in small or well-scoped samples. It works best when the goal is exploration rather than final measurement.
For decision-grade market research, however, accuracy depends on validation. You should review and refine the coding, quantify themes using auditable methods, and keep supporting evidence such as verbatim quotes and respondent identifiers attached to every major claim. ChatGPT should assist the process, not replace structured qualitative analysis.
How do you reduce hallucinations in market research analysis?
Hallucinations are more likely when inputs are large, ambiguous, or poorly scoped. To reduce risk, constrain the analysis intentionally. Analyze one question, segment, or wave at a time, and process large datasets in batches rather than all at once.
Require the model to back every insight with evidence, such as direct quotes or response IDs, and ask it to clearly separate what is supported by the data from what is a hypothesis or interpretation. Treat unsupported claims as signals to investigate further, not as findings.
What sample size should you use for pilot coding?
A pilot sample should be large enough to expose theme diversity, but small enough to review quickly and thoroughly. The exact size depends on how heterogeneous the responses are, but the principle is consistent across studies.
Start with a manageable subset, draft and apply the codebook, then review for overlap, ambiguity, and missing categories. Refine definitions and boundaries before scaling. Piloting first reduces rework later and improves consistency when analyzing larger volumes of qualitative data.
Can ChatGPT generate reliable crosstabs?
ChatGPT can help design or interpret crosstabs if you provide the underlying data or tables. It is useful for explaining patterns, drafting narrative summaries, or suggesting which comparisons may matter.
It should not be relied on to generate final counts, totals, or percentages directly from raw text. General AI chatbots can miscount, double-count, or produce inconsistent numbers across runs. For reporting and decision-making, quantitative outputs should always be produced and reconciled using auditable, repeatable methods.
The AI Copilot for interview and survey analysis
Focus Groups – In-Depth Interviews – Surveys